


เน็ต ท รู 1 วัน ไม่ ลด ส ปี ด

ตาข่ายทรูมูฟ เอช ราคาพิเศษ ดูแพ็คเกจทรูมูฟ เอช แบบต่างๆ เน็ต ท รู 1 วัน ไม่ ลด ส ปี ด ต้องการสมัคร True Internet สะดวก ง่าย รวดเร็ว ไม่ต้องกังวล เครือข่ายที่เหมาะสมคืออะไร? สามารถสมัครแพ็กเกจทรูต่างๆ เน็ตทรูรายวันไม่ลดสปีด 19 บาท ได้ในราคาพิเศษ ได้แก่ ทรูอินเทอร์เน็ตรายวัน, ทรูอินเทอร์เน็ต 3 วัน, ทรูอินเทอร์เน็ตรายเดือน ทรูเน็ตรายสัปดาห์และทรูอินเทอร์เน็ตไม่อั้นไม่ลดทอนในหลาย ๆ ด้าน ให้ลูกค้าทรูมูฟ เอช เน็ตทรูรายวันไม่ลดสปีด 17 บาท สัมผัสประสบการณ์ใหม่ด้วยวิธีการสมัครใช้งานอินเทอร์เน็ตทรูมูฟ เอช ที่ง่ายกว่า ไม่ว่าลูกค้าจะเป็นลูกค้าแบบเติมเงินก็ตาม เน็ตทรู20บาทไม่ลดสปีด หรือรายเดือนเพื่อความสะดวกในการใช้งาน หากคุณต้องการเพิ่มความเร็วของอินเทอร์เน็ตจริงหรือสั่งซื้อแพ็คเกจใหม่ของอินเทอร์เน็ตจริง ทำได้ง่ายมาก เกี่ยวกับเพจนี้
เน็ตทรูรายวันไม่ลดสปีด 19 บาท

สำหรับลูกค้าที่ต้องการดาวน์โหลด True Internet ออนไลน์ เน็ตทรูรายวันไม่ลดสปีด 19 บาท มีแพ็คเกจยอดนิยม เช่น True Internet 15 บาท, Max Internet Speed 500MB ในราคาพิเศษ, True Internet Daily Package ที่ซื้อได้จากเว็บไซต์ของเราเท่านั้น เน็ต ท รู 1 วัน ไม่ ลด ส ปี ด หรือหากต้องการใช้งานต่อเนื่องสามารถใช้ True Internet 15 บาท 512 kbps ต่อเนื่อง 500 MB ทรูอินเทอร์เน็ตรายวันราคาพิเศษและช่องทางออนไลน์ เน็ตทรูไม่ลดสปีด24บาท นอกจากนี้ยังมี ทรูอินเทอร์เน็ต 5 บาท โปรเพิ่มความเร็วเน็ตจริง 5 บาท เน็ตไม่อั้นไม่ลดความเร็ว 1 Mbps ให้ลูกค้าใช้งานได้ 1 ชม. เน็ตทรู 18 บาท ไม่ลดความเร็ว ไม่ลดความเร็ว เหมาะสำหรับการดาวน์โหลดไฟล์หรือดาวน์โหลดงานชั่วคราว
โปรเน็ตทรูไม่ลดสปีด
นอกจากนี้ยังมีโปรโมชั่น ทรู อินเทอร์เน็ต แบบเติมเงิน อื่นๆ อีกมากมาย โปรเน็ตทรูไม่ลดสปีด เช่น ทรู อินเทอร์เน็ต แพ็คเกจที่ความเร็วไม่ลดลง เช่น อินเทอร์เน็ตจริง 4 Mbps เน็ต ท รู 1 วัน ไม่ ลด ส ปี ด ซึ่งให้บริการอินเทอร์เน็ตจริงต่อวันและอินเทอร์เน็ตไม่จำกัด ไม่ลดสปีด แค่ 29 บาท โปรเน็ตทรูรายวัน และ True Internet Buy 1 Get 1 ใช้เป็นเน็ตจริงได้ 4Mbps ไม่ลดสปีด 2 วัน
หรือหากต้องการเล่น True Internet ด้วยความเร็วสูงสุดไม่มีสะดุดและตกหล่น โปรเน็ตทรูไม่ลดสปีด2วัน เราก็มี True Internet 6 Mbps ทั้ง True Pro-Net รายสัปดาห์ ความเร็วอินเทอร์เน็ตจริงไม่ จำกัด อินเทอร์เน็ตไม่ จำกัด เพียง 200 บาทและอินเทอร์เน็ตจริงไม่ จำกัด 6 Mbps ไม่ลดความเร็ว โปรเน็ตทรู รายเดือน เพียง 550 บาท พร้อมแพ็กเกจเติมเงินทรูเน็ตมูลค่าเพิ่มอีกมากมาย
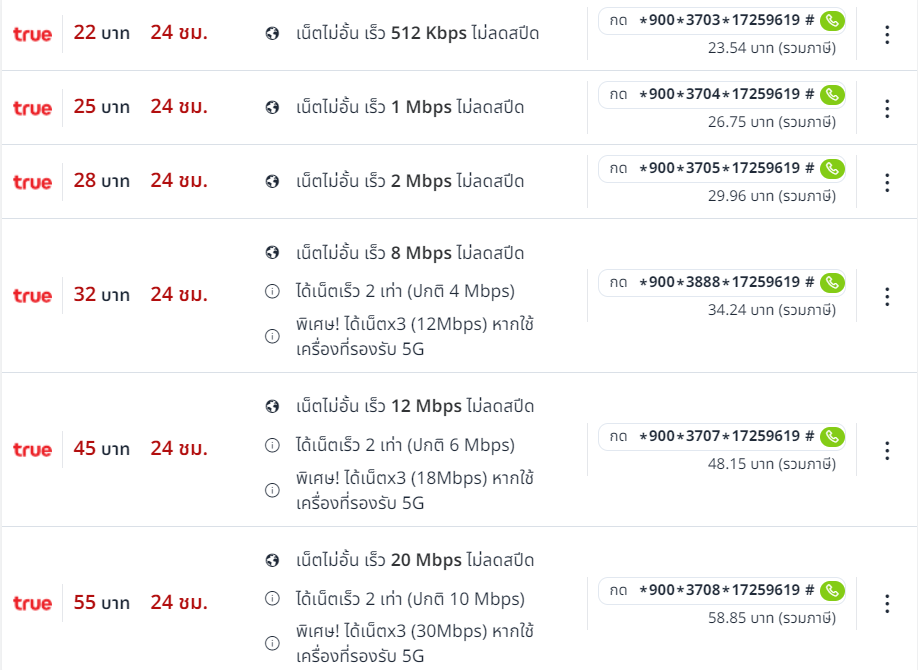
เน็ตทรูรายวัน 15 บาทไม่ลดสปีด
สำหรับลูกค้าทรูมูฟ เอช ที่ต้องการเพิ่มค่าบริการรายเดือนบนเว็บไซต์ทรู เน็ตทรูรายวัน 15 บาทไม่ลดสปีด มีโปรโมชั่นทรูอินเทอร์เน็ตรายเดือนให้คุณสมัครได้กับไลฟ์สไตล์ออนไลน์ที่หลากหลาย เน็ต ท รู 1 วัน ไม่ ลด ส ปี ด ทรูเน็ต จากแพ็กเกจ 9 บาท คือ ทรูอินเทอร์เน็ต ซื้อ 1 แถม 1 ฟรี ทรูอินเทอร์เน็ตรายวัน เน็ตทรู12บาทไม่ลดสปีด ไม่ลดความเร็ว 400MB เมื่อเทียบกับรุ่นเดิม ลูกค้าจึงใช้ได้เพียง 200MB หรือหากต้องการสมัคร เน็ตทรูไม่ลดสปีด24บาท True Internet 15 บาทต่อวัน ใหม่ มีโปรเน็ตจริง ซื้อ 1 แถม 1 เน็ตจริงไม่ลดความเร็ววันละ 800MB ให้เท่าเดิม ลูกค้าใช้ได้แค่ 400MB เท่านั้น
เน็ตทรูรายวัน แรงๆ สมัครเลย
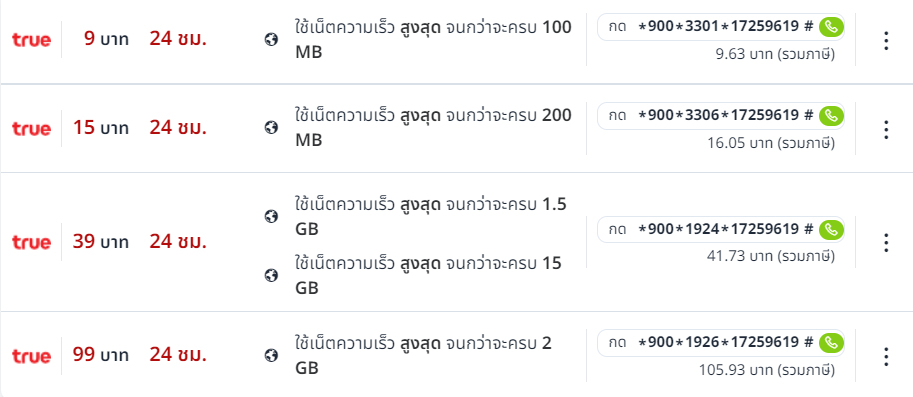
นอกจากนี้เรายังมีเน็ต 99 บาท เน็ตจริง 30 วัน ไม่ลดสปีด เน็ตทรูรายวัน แรงๆ ใช้ได้สูงสุด 2GB หรือใครอยากเติมเน็ตจริงสักสัปดาห์ ไม่จำกัดความเร็ว เรายังมีเน็ตรายสัปดาห์จริงที่ไม่ช้าเกินไป เน็ต ท รู 1 วัน ไม่ ลด ส ปี ด รวมถึงเน็ตรายสัปดาห์จริงต่ำกว่า 100 บาท เหมือนเล่นเน็ตจริง ซื้อ 1 แถม 1 ความเร็วเต็ม 8GB เพียง 99 บาท จากช่องปกติ 4GB ฟรี ซื้อ 1 แถม 1 สูงสุด เน็ตทรูรายวัน 15 บาทไม่ลดสปีด ความเร็ว 16GB ปกติ 8GB เพียง 149 บาท เรียกได้ด้วยแอคชั่นทรูมูฟ อีกหนึ่งช่องทางที่สะดวกในการสั่งซื้อแพ็คเกจแอปพลิเคชั่น โปรเน็ตทรูไม่ลดสปีด H Merit True Internet คือ ผ่านเว็บไซต์ของเรา ยังเร็วกว่าด้วยแพ็คเกจทรูอินเทอร์เน็ตที่หลากหลายซึ่งถูกที่สุดหากคุณใช้ทรูวอลเล็ทเพื่อสั่งซื้ออินเทอร์เน็ต เลือกตามไลฟ์สไตล์ของคุณ

เน็ตทรู3วันไม่ลดสปีด
เรารู้ว่าคุณกำลังมองหาข้อมูลบนอินเทอร์เน็ตจริงทุกวัน ไม่มีการชะลอตัว จ่ายล่วงหน้า เน็ตทรู3วันไม่ลดสปีด เราได้รวบรวมข้อมูลการโฆษณาทั้งหมดสำหรับคุณไว้ในที่เดียว เน็ต ท รู 1 วัน ไม่ ลด ส ปี ด รวมทุกอย่างและอัปเดตทุกเดือนด้วยข้อมูลล่าสุด คุณจึงไม่ต้องจำรหัสที่จะแตะ เน็ตทรู3วัน75บาท ที่คุณสามารถเลือกโปรโมชั่นรายวันได้ง่ายๆ สมัคร True Internet ทุกวัน เน็ตทรู40บาท3วัน รวดเร็ว ทันใจ เพียง 3 วินาที อย่าลืมบันทึกไซต์นี้ กดปุ่ม Apply เพื่อใช้งานได้ตลอด 24 ชม.

เน็ตทรูรายวันไม่ลดสปีด 17 บาท
นอกจากโปรโมชั่น 1 และ 2 วันแล้ว เว็บไซต์ของเรายังมี True Net Pro ไม่ลดสปีด เพิ่มโปรรายวัน 3 และ 5 วันด้วย เน็ตทรูรายวันไม่ลดสปีด 17 บาท เป็นทางเลือกของคุณโดยเพิ่มอีกเล็กน้อย เน็ต ท รู 1 วัน ไม่ ลด ส ปี ด ค่าใช้จ่ายรายวันจะถูกกว่าโปรทรูอินเทอร์เน็ตรายวันที่ 9, 15 หรือ 19 บาท ความเร็วไม่ลดแน่นอน ใช้งานอินเทอร์เน็ตจริงไม่จำกัด เน็ตทรู20บาทไม่ลดสปีด พลังไม่จำกัด มากเท่าที่คุณต้องการ ขั้นตอนการสมัครโปรโมชั่นออนไลน์ ไม่ลดสปีดเป็นเวลา 2 วัน
- เลือกการกระทำที่คุณชื่นชอบ
- กรอกจำนวนเงินรวมภาษี
- กด “สมัคร” หรือคัดลอกและวางรหัสบนโทรศัพท์มือถือของคุณแล้วกด “โทร”
- รอ 3 วินาทีเพื่อยืนยันการสมัคร SMS
จะเห็นได้ว่าโฆษณาทางอินเทอร์เน็ตจริง ๆ ไม่ได้ช้าลง 1 วัน เน็ตทรู15บาท มีหลายราคา ทั้ง 20 บาท 22 บาท 25 บาท 28 บาท และ 29 บาท แต่มีโปรเน็ตทรู 2 วัน ไม่ลดสปีด และ 3 วันนั้นราคาต่อวันสูงกว่าค่าเฉลี่ย ถูกกว่าทรูเน็ตรายวัน 15 บาท
และถูกกว่าทรูเน็ตรายวันไม่ลดสปีด 19 บาท สำหรับโปรทรูเน็ตรายวัน ไม่ลดสปีด 3 วัน โทรฟรีทรูมูฟ เอช ราคาสุดท้าย จากปกติ 60 บาท ลดเฉลี่ยเหลือเพียง 20 บาทต่อวัน คุณสามารถเพลิดเพลินกับอินเทอร์เน็ตจริง ความเร็วไม่จำกัดที่แข็งแกร่ง 1 MB พร้อมการเชื่อมต่อเครือข่ายจริงตลอด 24 ชั่วโมง 3 วันเต็ม!
เน็ต ท รู 1 วัน ไม่ ลด ส ปี ด สมัครง่าย
REAL 5G READY 4G POWER UP 5G พร้อมรองรับเครือข่าย 4G/4G+ ที่ทรงพลังกว่า เน็ต ท รู 1 วัน ไม่ ลด ส ปี ด สมบูรณ์กว่า เร็วกว่า และสามารถตอบสนองความต้องการของทั้ง 77 จังหวัดในประเทศไทย เน็ตทรู2วันไม่ลดสปีด แท้จริงแล้วเป็นผู้นำเครือข่ายอัจฉริยะ โอเปอเรเตอร์เดียวที่มี 7 คลื่นมากที่สุดในประเทศไทย: 700 MHz, 850 MHz, 900 MHz, 1800 MHz, 2100 MHz, 2600 MHz และ 26 GHz
นอกจากจะมีคลื่นความถี่ต่างกันถึง 7 แถบแล้ว การใช้แต่ละพื้นที่ยังเหมาะสมสำหรับการปรับคลื่นความถี่ในแถบใดๆ สมัครเน็ตทรู ที่ครอบคลุมอยู่แล้ว ทรูมูฟ เอช ยังเพิ่มแบนด์วิดธ์หรือแบนด์วิดธ์เป็น 3 เท่า เพื่อให้ลูกค้าใช้เวลาเดียวกันได้อย่างรวดเร็ว เรียบเนียนไร้ที่ติ
เสาสัญญาณครอบคลุมทั่วประเทศไทย สมัครเน็ตทรู3วัน พร้อมใช้งานใน 77 มาร์เซ (เมือง) และขยายพื้นที่ให้บริการใหม่อย่างต่อเนื่องเพื่อสร้างประสบการณ์ใหม่ ในเครือข่ายอัจฉริยะที่มีความเร็วและประสิทธิภาพสูงสุดสำหรับลูกค้าจริงทุกคน ด้วยคลื่นความถี่เต็มรูปแบบและการขยายแบนด์วิธไม่จำกัดในประเทศไทย ให้คุณสัมผัสไลฟ์สไตล์ของคนในยุคดิจิทัลได้อย่างแท้จริง

คำถามที่พบบ่อย
Q : เน็ตจริงทุกวันไม่ลดสปีด ราคาเริ่มต้นเท่าไร ?
A : โปรเน็ตทรูรายวันล่าสุด 9 บาท
Q : ใช้ True Internet ทำงานอย่างมีประสิทธิภาพทุกวันได้อย่างไร?
A : ความเร็วสูงสุดที่คุณสามารถใช้ได้ขึ้นอยู่กับประเภทของซิมการ์ดและพื้นที่ใช้งาน 4G = 100 Mbps, 3G = 42 Mbps
Q : เน็ตจริงทุกวันไม่ลดสปีด
A : 1. เลือกโปร 2. โหลดมือถือของคุณพร้อมภาษีเงินแล้ว 3. คลิกที่ “สมัคร” 4. รอการยืนยัน
Q : หากมีปัญหาในการเข้าถึงอินเทอร์เน็ตจริงทุกวันโดยไม่ให้ช้าลง จะเข้าใช้ช่องทางใดได้บ้าง ?
A : คุณสามารถติดต่อศูนย์บริการทางโทรศัพท์ 1242